
새벽을 밝히는 붉은 달
[Hadoop] YARN capacity-scheduler 사용 기록 본문
본 글은 쓰기에 앞서, 정보 전달의 목적을 띈 글이라기보다 내가 사용했던 capacity-scheduler에 대해 기록을 남기기 위함을 알린다.
1. YARN
하둡의 클러스터 자원 관리 시스템인 YARN은 Hadoop2에서 맵리듀스의 성능을 높이기 위해 처음 도입되었다. YARN은 클러스터 전체 자원의 사용량을 관리하는 리소스 매니저와 컨테이너를 구동하고모니터링하는 역할을 하는 노드 매니저 등 두 가지 유형의 장기 실행 데몬을 통해 핵심 서비스를 제공한다.
2. YARN의 실행 구조
클라이언트는 YARN에서 애플리케이션을 구동하기 위해 리소스 매니저에 접속하여 애플리케이션 마스터 프로세스의 구동을 요청한다. 리소스 매니저는 컨테이너에서 애플리케이션 마스터를 시작할 수 있는 노드 매니저를 하나 찾는다. 애플리케이션 마스터가 딱 한 번만 실행될지는 애플리케이션에 따라 다르다. 애플리케이션 마스터가 단순한 계산을 단일 컨테이너에서 수행하고 그 결과를 클라이언트에 반환한 후 종료되거나, 리소스 매니저에 더 많은 컨테이너를 요청한 후 분산 처리를 수행하는 경우도 있다.
3. YARN 스케줄링
우리가 가진 자원은 제한되어 있고 클러스터는 매우 바쁘고 어떤 애플리케이션은 요청이 처리될 때까지 기다려야 한다. YARN 스케줄러의 역할은 정해진 정책에 따라 애플리케이션에 자원을 할당하는 것이다. 다만 사용자의 환경에 따라 적절한 정책이 다를 수 있기 때문에, YARN은 스케줄러와 설정 정책을 사용자가 직접 선택할 수 있도록 기능을 제공하고 있다.
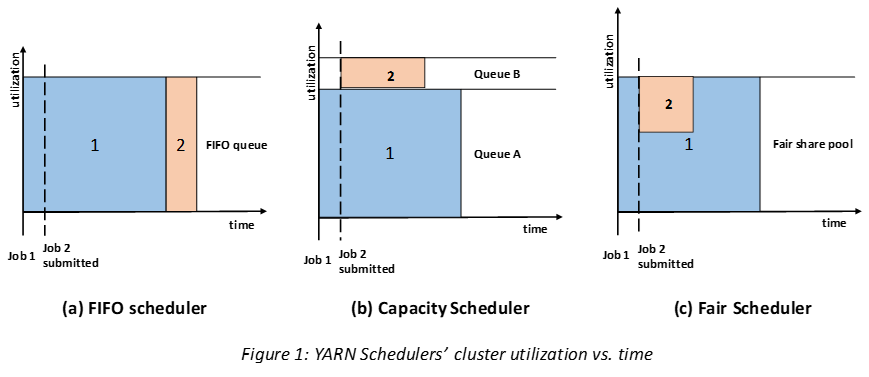
3-1. FIFO Scheduler
FIFO scheduler는 선입선출 방식으로 동작하는 scheduler로, 큐에 처음으로 들어온 애플리케이션 요청을 먼저 할당하고 이 요청을 처리한 후 큐에 있는 다음 애플리케이션 요청을 처리한다. 쉽지만 공유 클러스터 환경에서는 대형 애플리케이션이 클러스터의 모든 자원을 점유하여 다른 애플리케이션들은 계속 대기하고 있는 상태가 발생할 수 있기 때문에 공유 클러스터 환경에서는 아래 두 스케줄러를 사용하는 것이 권장된다.
3-2. Capacity Scheduler
Capacity Scheduler는 작은 잡은 제출되는 즉시 분리된 전용 큐에서 처리해준다. 이렇게 되면 해당 큐는 잡을 위한 자원을 미리 예약해두기 때문에 전체 클러스터의 효율성은 떨어지며, 대형 잡은 FIFO Scheduler를 사용했을 때보다 늦게 끝난다.
3-3. Fair Scheduler
Fair Scheduler는 실행 중인 모든 잡의 자원을 동적으로 분배하기 때문에 자원의 가용량을 예약할 필요가 없다. 만약 대형 잡 하나만 실행 중이라면 전체 리소스를 사용하다가, 작은 잡이 추가되면 클러스터 자원의 절반을 이 잡에 할당한다. 다만 두 번째 잡이 제출된 이후 클러스터 자원을 나눠 받을 때까지 약간의 시간차가 있을 수도 있는데, 첫 번째 잡이 사용하고 있는 리소스가 해제될 때까지 기다려야 하기 때문이다.
4. Capacity Scheduler 사용기
4-1. 구조 및 설정
처음에 염두를 두고 있었던 것은 Capacity Scheduler와 Fair Scheduler 두 가지였는데, 결론적으로 Capacity Schduler만 테스트를 해보았다. 큐 구조를 다음과 같이 짰다고 했을 때, root 하위의 Prod와 Dev 큐가 서로 간 리소스를 침범하면 안 됐기 때문이다.
root
|_ Prod
|_Dev
|_ alpha
|_ beta
Capacity Scheduler는 앞서 설명했듯이 분리된 전용 큐를 가지며 클러스터 가용량의 지정된 부분을 사용하도록 설정할 수 있다. 하나의 단일 잡은 해당 큐의 가용량을 넘는 리소스를 사용할 수 없는 것을 원칙으로 하나, 몇몇 설정을 통해 다른 큐의 리소스가 남을 경우 해당 리소스를 가져와서 할당할 수가 있다. 이러한 방식을 큐 탄력성(queue elasticity)라고 한다.
아래 항목들을 이용해 큐 탄력성을 기반으로 위의 구조와 같은 큐 간 리소스를 어떻게 사용하는지 테스트를 해보았다.
- yarn.scheduler.capacity.<queue-path>.capacity : 큐 별로 minimum capacity를 설정한다. 이때, 큐 별로 할당된 capacity의 합은 100%여야 한다.
- yarn.scheduler.capacity.<queue-path>.maximum-capacity : 큐 별로 maximum capacity를 설정한다. 다른 큐에서 리소스를 사용하지 않아 리소스를 더 사용할 수 있을 때, maximum capacity 이내까지 리소스를 늘려서 사용이 가능하다. maximum-capacity를 제한하지 않는다면 전체 가용량을 사용할 수 있게 된다.
- yarn.scheduler.capacity.<queue-path>.minimum-user-limit-percent : 큐 내에 유저들이 사용할 수 있는 최소 리소스를 설정한다.
- 만약 25로 설정되어 있다면
- 두 명의 유저가 job을 제출했을 경우 각각 큐의 50%까지 리소스를 사용한다
- 세 명의 유저가 job을 제출했을 경우 각각 큐의 33%까지 리소스를 사용한다
- 네 명의 유저 또는 그 이상의 유저가 job을 제출했을 경우 각각 큐의 25%까지 리소스를 사용한다.
- 만약 25로 설정되어 있다면
- yarn.scheduler.capacity.<queue-path>.user-limit-factor : (queue capacity * user-limit-factor) 만큼 user가 다른 큐의 리소스를 가져와서 리소스를 추가로 더 사용이 가능하다. 단, 큐의 maximum capacity 까지만 사용이 가능하다.
4-2. 사용 기록
- prod와 dev 간 capacity와 maximum-capacity를 같게 설정했더니, 서로 간의 리소스 침범이 없던 것을 확인했다.
- dev 하위에 있는 alpha, beta에 대해서도 capacity의 합은 100%이어야 한다. dev에 할당된 리소스를 지정한 퍼센트만큼 나눠가지게 된다.
- 큐 탄력성을 통해 다른 큐의 리소스를 가져왔을 때, 해당 잡이 끝나기 전까지는 리소스를 가져온 큐에 잡이 제출되더라도 리소스를 반환하지 않는다. 만약 수행시간이 오래 걸리는 잡이라면 다른 큐는 해당 잡이 끝날 때까지 기다려야하기 때문에, 다른 큐의 리소스를 얼마나 가져올지 신중하게 결정해야 한다.
- 다만 큐를 삭제하는 것외에는 잡을 사용하고 있는 와중에도 큐에 대한 설정을 변경할 수 있기 때문에, 테스트는 간단히 진행하고 실제 사용자들이 사용하는 양상을 지켜보며 큐 간 리소스를 얼마만큼 뺏어올 것인지 수정하면서 적절한 값을 찾아나가는 것이 좋아보인다.
- 큐를 삭제할 때는 큐에 제출된 잡이 없어야 삭제가 가능하다고 하다. 아직 실제로 삭제를 해본 적은 없다.
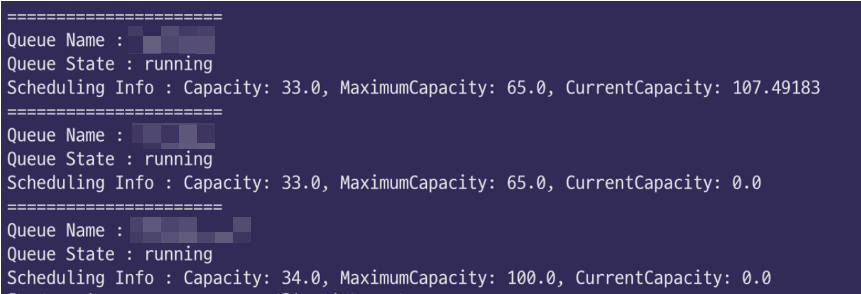
- mapred queue -list 명령어를 사용하면 현재 사용중인 큐의 scheduling info를 살펴볼 수 있는데, current capacity가 100을 넘는 것을 볼 수 있다. 처음에 MaximumCapacity보다 더 많이 사용하고 있는 줄 알고 놀랬는데, current capacity에 대한 정의가 달랐다. 만약 current capacity가 아래와 같이 107이라면, 할당된 capacity인 33.0의 107%를 사용하고 있다는 뜻이다. 자세한 글은 클라우데라에 올라온 Q&A를 참고하자.
- yarn.scheduler.capacity.<queue-path>.accessible-node-labels 를 통해 GPU 등 특정 리소스를 어떤 큐들이 얼마나 사용가능하도록 지정하는 것이 가능하다.
Reference
하둡 완벽 가이드(4판), 한빛미디어, 톰 화이트
https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html
'Data Engineering' 카테고리의 다른 글
| Trino와 Presto 톺아보기 (1) | 2023.09.02 |
|---|---|
| [Airflow] on_failure_callback에서 Xcom 사용하기 (1) | 2023.02.05 |
| [NLP] FastText 의 pretrained-model에 text-classification을 위한 추가학습하기 (0) | 2021.09.26 |
| [밑바닥부터 시작하는 딥러닝] 퍼셉트론 (0) | 2021.04.10 |


