
새벽을 밝히는 붉은 달
[SQL] 1. 기본적인 SQL 사용법 본문
이 글은 Standford 대학의 Jennifer Widom 교수님의 강의노트를 바탕으로 postgreSQL을 사용하여 정리한 글입니다.
잘못된 내용, 혹은 수정해야할 사항이 있다면 댓글로 알려주시면 감사하겠습니다.
SQL의 SELECT 문은 다음과 같은 구조를 기본적으로 가지고 있다.
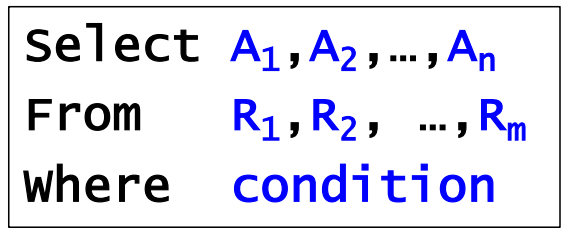
그럼 예제를 통해 SELECT 문의 활용에 대해서 알아보자.
table의 가로는 tuple 혹은 row라고 부르며,
table의 세로는 attribute 혹은 column이라고 부른다.
이 글에서는 table의 가로를 tuple, 세로를 attribute라고 부르겠다.
먼저, 다음과 같은 College, Student, Apply의 3가지 table이 있다고 하자.
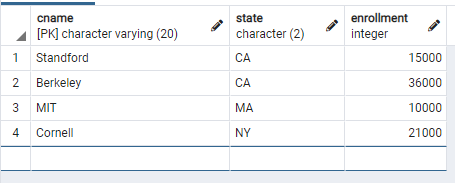
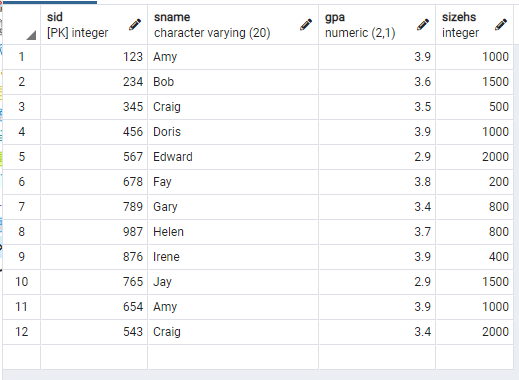
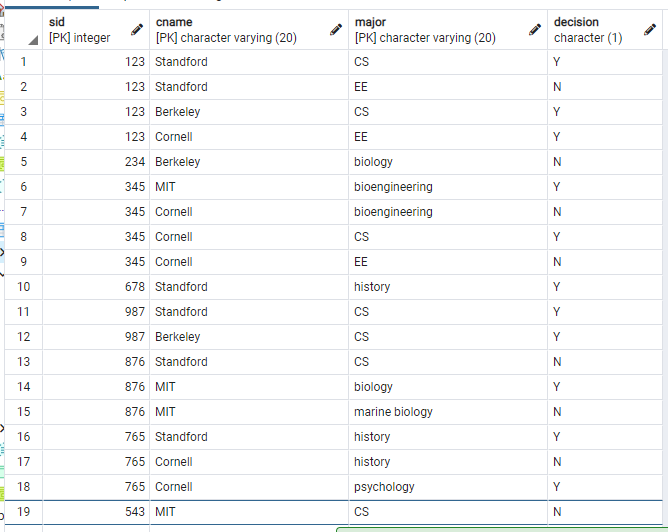
나는 학생들 중에, GPA가 3.6 보다 큰 학생들의 학번과 이름, GPA를 알고 싶다.
그렇다면 다음과 같은 SQL query를 통해 구할 수 있다.
select sID, sName, GPA from Student where GPA > 3.6;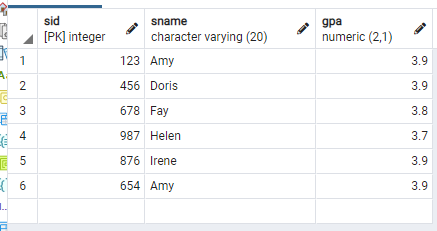
위의 query의 뜻은 다음과 같다.
'Student table에서, GPA > 3.6 을 만족하는 tuple의 sID, sName, GPA를 차례대로 출력해달라'
만약 위와 같은 조건이지만, sID와 sName만을 출력하고 싶다면 다음과 같은 query를 작성하면 된다.
select sID, sName from Student where GPA > 3.6;
두 개의 table을 비교하여 출력하는 query문을 작성할 수도 있다.
Apply table과 학교에 지원한 사람의 ID와 Student table에서 학생의 ID가 같은 사람의 이름과 전공을 구하고 싶다면 다음과 같이 query를 작성하면 된다. 이때, Student table과 Apply table에 sID라는 attribute가 둘 다 존재하기 때문에, 어떤 sID를 뜻하는지 확실하게 알려주기 위해서 (테이블 명).(attribute 명) 으로 해준다.
select sName, major from Student, Apply where Student.sID = Apply.sID;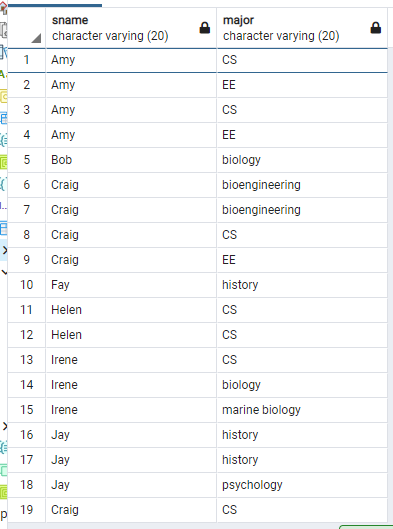
그런데, Amy의 경우 1번과 3번, 2번과 4번처럼 중복된 값이 2번 출력되었다. 이는 Amy가 대학에 4번 apply를 했기 때문에 해당 경우를 모두 출력하는 것이다. 여기서 SQL은 query의 결과에 중복된 값이 있더라도, 제거하지 않고 출력하는 것을 알 수 있다.
만약 query의 결과에 중복된 내용이 없길 바란다면 distinct 를 쓰면 된다.
select distinct sName, major from Student, Apply where Student.sID = Apply.sID;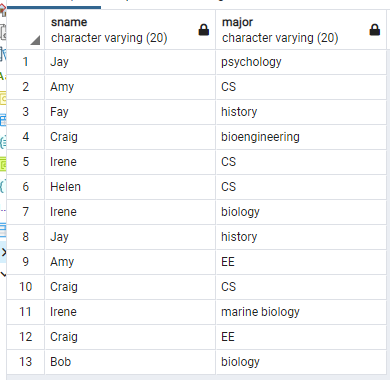
지금까지는 where 구절에 하나의 조건만이 있었다. 그러나 여러개의 조건을 추가하고 싶다면 어떻게 해야 할까?
각각의 조건을 and 를 이용하여 이어주면 된다.
만약
조건 1) Apply table과 학교에 지원한 사람의 ID와 Student table에서 학생의 ID가 같고,
조건 2) 그들의 출신 고등학교 학생 수의 size가 1000보다 작으며,
조건 3) 전공은 CS,
조건 4) 학교는 Standford에 재학 중인
사람의 이름과 GPA, 그리고 학교 입학의 승인 여부를 알고 싶다면 다음과 같이 query를 하면 된다.
select sName, GPA, decision
from Student, Apply
where Student.sID = Apply.sID and sizeHS < 1000 and major = 'CS' and cName = 'Standford';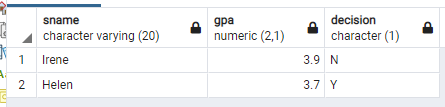
위에서 설명했던 내용이지만 한 번 더 짚고 넘어가자.
여러 개의 table을 참조하는데 같은 이름의 attribute가 있다면, 어느 table의 attribute를 의미하는 것인지 확실하게 표시를 해주어야 한다. 만약 확실하게 표시하지 않는다면, error가 발생하는 것을 볼 수 있다.
다음과 같은 예시를 살펴보자.
select cName
from College, Apply
where College.cName = Apply.cName and enrollment > 20000 and major = 'CS';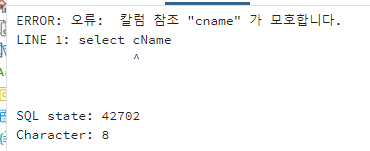
위의 query의 결과가 우리가 의도한대로 나오도록 cName이 어느 table의 cName인지 확실하게 표시하고 query를 날려보자.
select College.cName
from College, Apply
where College.cName = Apply.cName and enrollment > 20000 and major = 'CS';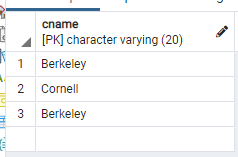
query는 error 없이 잘 동작했지만, 중복된 값이 출력되었다. distinct를 써서 중복된 값을 제거해보자.
select distinct College.cName
from College, Apply
where College.cName = Apply.cName and enrollment > 20000 and major = 'CS';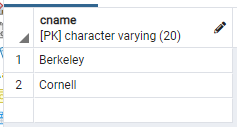
지금까지는 2개의 table을 동시에 비교하는 query를 작성해보았다. 이번에는 3개의 table 모두를 비교하는 query를 작성해보도록 하자.
만약, Apply한 사람의 ID와 학생의 ID가 같으면서, College table에 존재하는 대학에 지원한 학생의 ID, 이름, GPA, 대학 이름, 대학의 인원수를 구하고 싶다면 다음과 같이 query를 하면 된다.
select Student.sID, sName, GPA, Apply.cName, enrollment
from Student, College, Apply
where Apply.sID = Student.sID and Apply.cName = College.cName;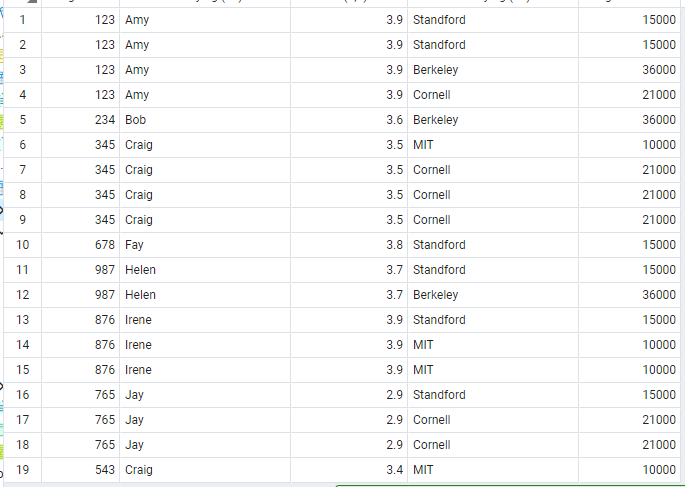
만약에 위 결과를 GPA 내림차순으로 보고 싶다면 어떻게 해야할까? 그땐 where 뒤에 order by 에 desc 옵션을 붙여서 쓰면 된다.
select Student.sID, sName, GPA, Apply.cName, enrollment
from Student, Apply, College
where Student.sID = Apply.sID and Apply.cName = College.cName
order by GPA desc;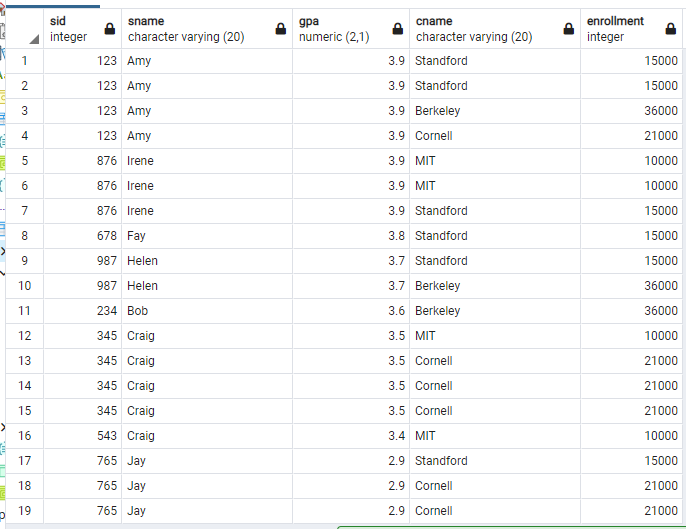
여기에 한술 더 떠서, GPA는 내림차순으로 출력을 하되, GPA가 같을 경우 대학의 인원 오름차순으로 출력을 하고 싶어졌다. 그때는 order by GPA desc 뒤에 enrollment를 써서, 가장 먼저 GPA 내림차순으로 보여주되, GPA가 같을 경우 enrollment 오름차순으로 보여주라고 알려주면 된다.
select Student.sID, sName, GPA, Apply.cName, enrollment
from Student, College, Apply
where Apply.sID = Student.sID and Apply.cName = College.cName
order by GPA desc, enrollment;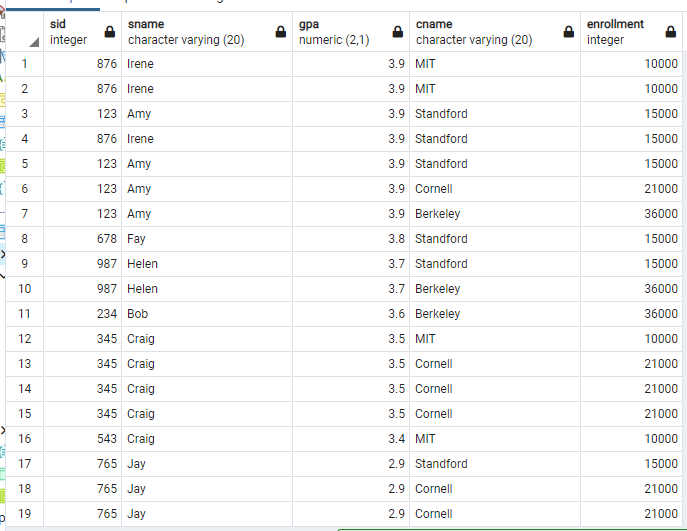
이때, enrollment의 뒤에 오름차순을 뜻하는 asc를 써도 되고, 안 써도 된다. 왜냐하면 order by의 default값은 오름차순이기 때문이다.
select Student.sID, sName, GPA, Apply.cName, enrollment
from Student, College, Apply
where Apply.sID = Student.sID and Apply.cName = College.cName
order by GPA desc, enrollment;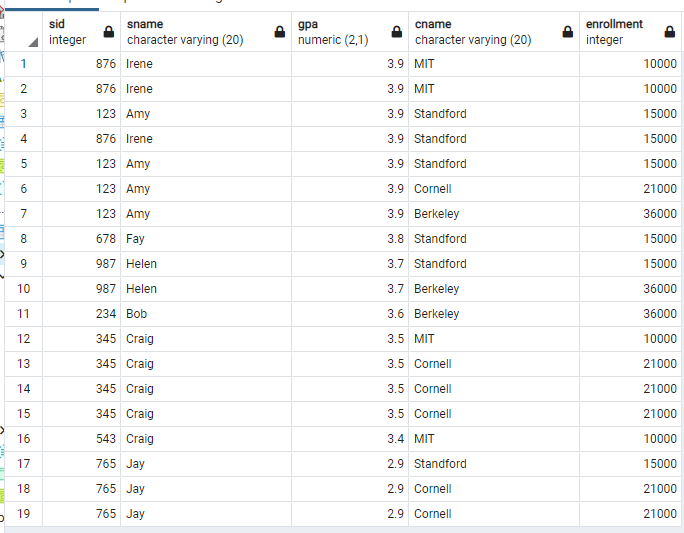
만약에 특정 글자를 포함하고 있는지 알고 싶다면 어떻게 해야할까? 이때는 like를 쓰면 된다.
예를 들어, Apply한 사람들 중 major의 이름에 bio가 들어가는 사람들의 ID와 major를 구하고 싶으면 다음과 같이 query를 하면 된다.
select sID, major
from Apply
where major like '%bio%';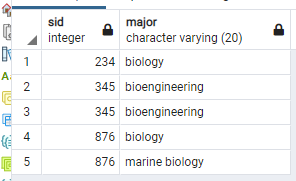
여기서 % 의 의미는 어떤 글자가 와도 상관이 없다는 뜻이다. 즉, %bio%는 글자 내에 어디든 bio라는 글자가 들어가있으면 된다는 뜻이다. 만약에 bio% 라고 한다면, 이것은 bio로 시작하는 major를 찾아달라는 이야기이다.
select sID, major
from Apply
where major like 'bio%';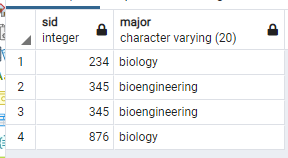
지금까지는 조건에 맞는 tuple과 attribute의 값만을 출력하는 것을 살펴보았다. 그런데, 만약에 table의 전체 모습을 보고 싶다면 어떻게 해야 할까? 그럴 때는 *(asterisk) 를 쓰면 된다.
select * from Student;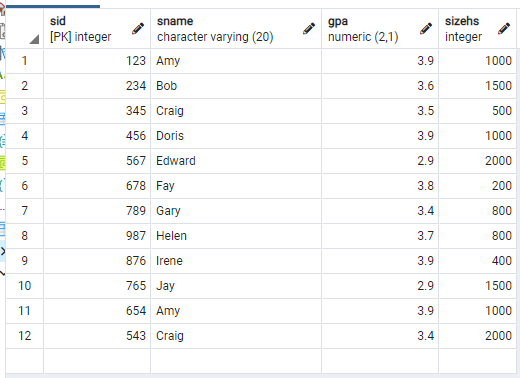
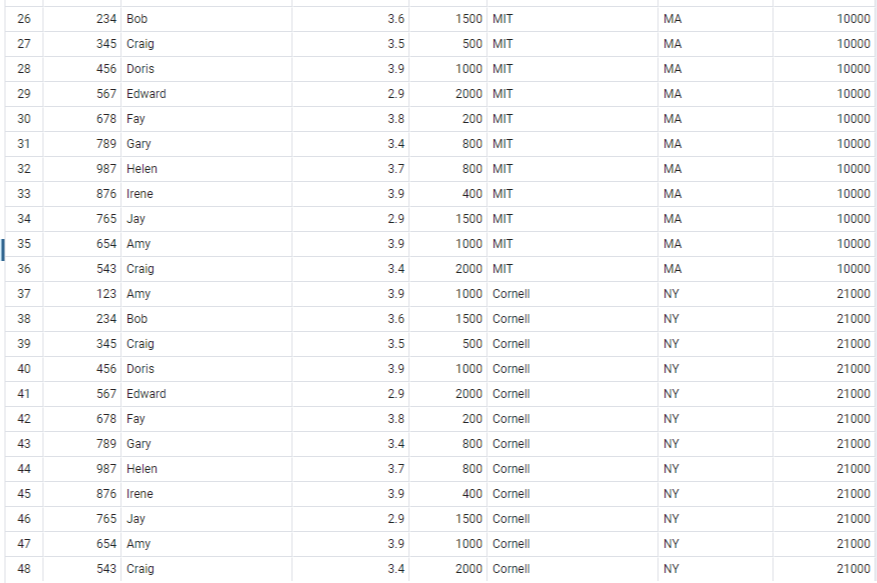
두 개의 table을 합쳐서 보는 것도 가능하다. 단, 이때는 한 table과 다른 table의 tuple을 각각 1:1로 매치시켜서 보여준다.
즉, 만약 첫 번째 table의 tuple의 개수가 n개, 두 번째 table의 tuple의 개수가 m개라면 n*m개의 tuple의 개수를 보여준다.
select * from Student, College;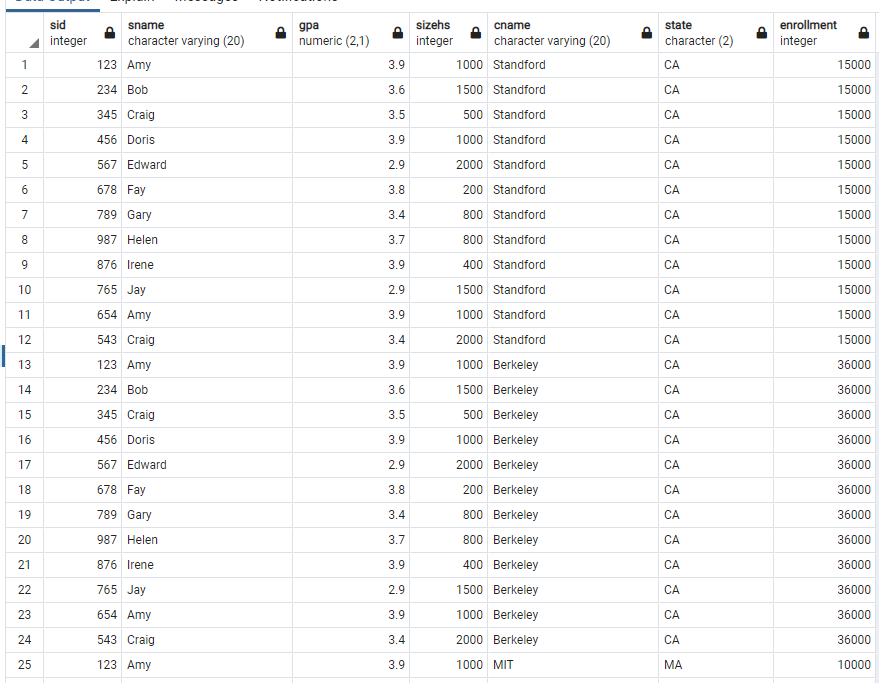
SQL은 프로그래밍 언어답게, 값을 계산하여 보여주는 것도 가능하다.
학생들의 ID, 이름, GPA, 고등학교의 학생 수, 그리고 GPA를 sizeHS/1000.0 과 곱한 값을 보고 싶다면 다음과 같이 query하면 된다.
select sID, sName, GPA, sizeHS, GPA*(sizeHS/1000.0) from Student;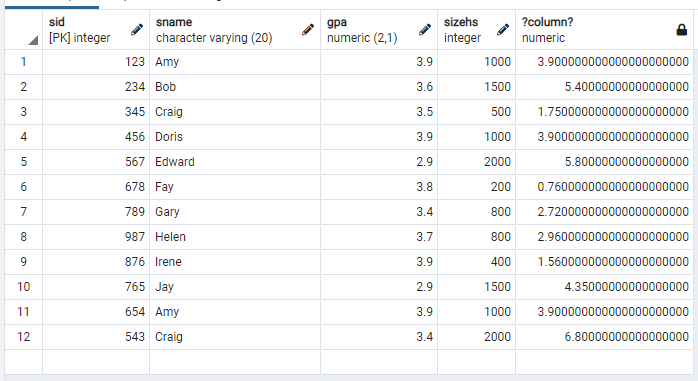
위와 같은 query를 하면, 계산된 결과값이 출력되는 것을 알 수 있다.
만약 계산하여 출력되는 attribute의 이름을 지정해주고 싶다면, as 를 쓰면 된다.
select sID, sName, GPA, sizeHS, GPA*(sizeHS/1000.0) as scaledGPA from Student; 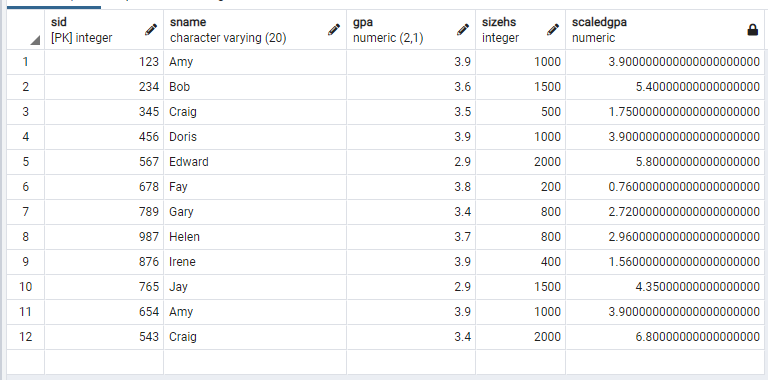
'Develop > Database' 카테고리의 다른 글
| 벡터 데이터베이스 톺아보기 (0) | 2023.11.05 |
|---|---|
| [Redshift] Column does not exist (0) | 2022.10.22 |
| [MongoDB] cannot connect to the mongodb at localhost 27017 (4) | 2021.08.09 |


